

We Shipped. Finally.
How we pushed 4x B200s to their absolute limits, broke production on launch day, and why FP8 KV cache is actually slower on Blackwell (yes, really)

Well, well, well... look who’s finally shipping something.
After postponing more times than I care to admit. After mass-panic Discord messages at 2am. After one full month of crunch that turned my hair even greyer than it already was.
Omea’s free demo is live.

Go to omea.ai. Play a Viking survival horror story. Talk to NPCs who actually listen. Make choices that actually matter. Experience what happens when AI stops being a chatbot and starts being a Game Master.
This thing almost didn’t ship. Three times.
And I want to tell you exactly why.
If you’ve been wondering where I disappeared to for the past month - no Substack posts, no LinkedIn updates, total radio silence - this is why. Sometimes you have to choose between talking about building and actually building.
I chose building.
The Viking Who Almost Wasn’t
The demo story was supposed to be small. Simple. A quick proof-of-concept to show what Omea can do.
It turned into something else entirely.
A survival horror sandbox set in a frozen Viking world. Memorable NPCs with actual personalities. Easter eggs hidden in places you won’t find on your first playthrough. Or your second. Genuinely unlimited freedom - sneak, talk, fight, run, manipulate, befriend, betray. The AI doesn’t care which path you choose. It adapts.
This happened because our Game Director Darek kept pushing for “just one more thing” and our QA testers kept finding ways to break it (and then ways to make the breaking interesting), and our coders kept fixing bugs in real-time while the game designers kept adding depth.
Skunk Works in action. Small team. Fast iteration. Ship and fix and ship again.
But none of that matters if the servers can’t handle it.
And boy, did we have server problems.
The Inference Stack From Hell
Warning: full nerd mode engaged. If you’re here for the vibes, skip to “The Grind” section. If you want to know why we spent three weeks fighting FlashInfer version incompatibilities, buckle up.
Phase 0: vLLM (the baseline disaster)
We started where everyone starts: vLLM.
vLLM 0.15.1 on 8x B200 GPUs. Our NIA model (that’s Narrative Intelligence Architecture - our custom 350B+ parameter MoE beast). The results?
75 tokens per second per user
16 second time-to-first-token
641 tok/s total at 15 concurrent users
For context: 16 seconds TTFT means the player asks a question and waits... and waits... and waits... before the AI even starts responding. Unplayable.
The core problem: no speculative decoding. MTP (Multi-Token Prediction) crashed with a segfault on the first forward pass with FP8 MoE on B200. Old vLLM. No NIA-specific optimizations.
Dead end.
Phase 1: Stock SGLang (broken in new ways)
Tried SGLang with EAGLE speculation on 4x H200. Different hardware, different framework, different problems.
Short prompts? Worked fine.
Long prompts (14K+ tokens)? The model produced degenerate garbage. Complete nonsense. Like it had a stroke mid-sentence.
Root cause: FlashInfer attention backend bug on Hopper architecture. Nothing to do with EAGLE - same degeneration without it.
Another dead end.
Phase 2: The Breakthrough
We found an experimental SGLang fork optimized for B200 hardware. Some very helpful friends from San Jose pointed us in the right direction.
Three things made it work:
1. The right attention backend. B200’s default is trtllm_mha. Flash Attention 3 throws a ValueError on sm_100 (Blackwell’s architecture). Flash Attention 4 exists and is Blackwell-native (2x faster than FA3 for prefill), but it’s prefill-only - and EAGLE’s draft worker inherits the prefill backend. So FA4 + EAGLE throws “EAGLE is not supported in attention backend fa4”.
We’re stuck with trtllm_mha. It works.
2. Architecture-specific fusions. NIA is a Mixture-of-Experts model with shared experts that run on every token. Stock SGLang runs these as separate operations. The fork fuses shared expert computation into the MoE routing pass - eliminating redundant memory transfers. This alone gave +23.7% TTFT improvement.
Plus QK-Norm-RoPE fusion (three separate kernel launches become one), and async transfer that overlaps data movement with computation during MoE routing. That last trick hides PCIe/NVLink latency behind GPU compute - up to 1 second TTFT reduction. A friend from a robotics company shared that insight. Wasn’t my idea.
3. The correct reasoning parser. The reasoning parser is broken in this SGLang build. It never detects the </think> tag, causing infinite generation until max tokens. We had to use the deepseek-r1 parser instead, which works because NIA uses the same <think>...</think> format as DeepSeek-R1.
Yes, really. Production inference serving hacked together with a parser swap.
The Version Hell
Beyond the fork itself, getting a working stack required pinning exact dependency versions. And I mean exact.
FlashInfer 0.6.2 - Not 0.6.1 (broken MoE routing). Not 0.6.4 (breaks the trtllm_mha API). Exactly 0.6.2.
transformers 4.57.3 - Not 4.57.1 (crashes the tokenizer with “ValueError: Converting from SentencePiece and Tiktoken failed”). Not 5.0.0 (silently destroys EAGLE acceptance rate from 0.82 to 0.25 - no error message, just degraded performance). Exactly 4.57.3.
MNNVL stubs - FlashInfer 0.6.2’s MNNVL module uses the old cuda-python API (from cuda import cuda) which fails with cuda-python 12.x. We wrote 12 stub classes and wrapped all MNNVL imports in try/except blocks. Single-node inference doesn’t need multi-node NVLink, but the imports crash without the stubs.
The result after all this: 2.2x per-user TPS (165 vs 75) and 4.6x lower TTFT (3.5s vs 16s) versus vLLM on the same hardware.
Worth every hour of debugging. Barely.
EAGLE Speculation: Where the Magic Happens
EAGLE (Early-exit Augmented Generation for Large language models Efficient decoding) in SGLang is actually the same algorithm as NEXTN - they’re aliases. The model’s built-in MTP head serves as the draft model.
Our configuration:
SGLANG_ENABLE_SPEC_V2=1
--speculative-num-steps 3
--speculative-eagle-topk 1
--speculative-num-draft-tokens 43 speculation rounds per step, top-1 candidate per round, 4 draft tokens total. This is the sweet spot. More steps didn’t improve acceptance rate and added overhead. topk > 1 increases memory without meaningful throughput gains.
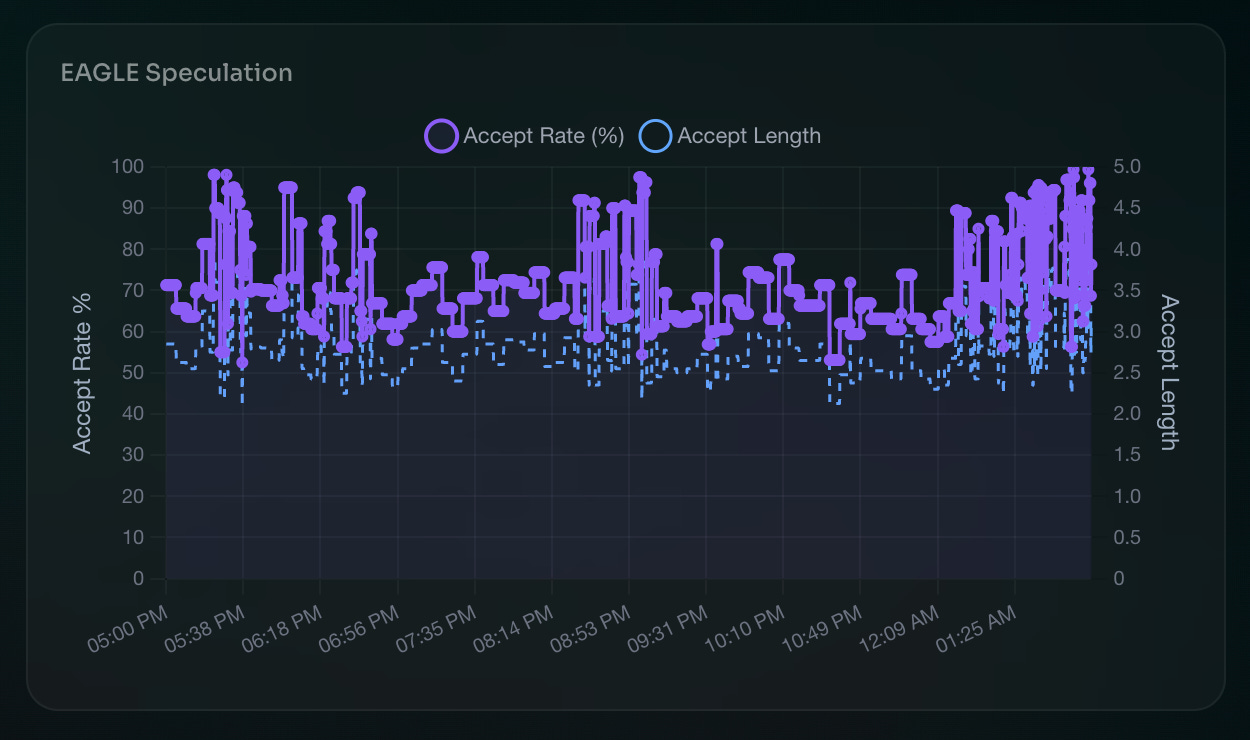
Measured acceptance rates:
BF16 KV cache: 78% acceptance, average 3.28 tokens/step
FP8 KV cache: 67% acceptance, average 2.66 tokens/step
That 14% acceptance drop with FP8 KV? It matters. A lot. More on this below.
Here’s something wild we discovered: EAGLE has a profound effect on reasoning behavior. Without EAGLE, NIA generates 2,000-10,000 reasoning tokens per request. With EAGLE, reasoning consistently collapses to approx 500 tokens. And that is before Pena’s magic…
We believe EAGLE’s token acceptance patterns effectively “shortcut” the model’s reasoning chains - speculated tokens that match the model’s likely next output get accepted in batches, preventing the model from going down long deliberation paths.
This is why NVFP4 without EAGLE was 5x worse on TTFT - without the speculation shortcutting, the model’s reasoning explodes.
The counterintuitive discovery: BF16 KV is faster on Blackwell
This one broke my brain for a day.
Weights: FP8 (almost 400GB on disk). Aggressive - 8-bit for a 500B+ parameter MoE model.
KV cache: BF16 (16-bit).
Wait, what? Shouldn’t FP8 KV be faster? Half the memory bandwidth for cache reads?
On H200/H100: yes. FP8 KV is +12.6% faster on H200, +27.7% on H100. Those architectures are memory-bandwidth-bound.
On B200/B300: FP8 KV is 18.8% slower than BF16.
The reason: Blackwell’s faster memory subsystem shifts the bottleneck from bandwidth to compute. The FP8 quantize/dequantize kernels add extra 23 microseconds per layer. With NIA’s 92 attention layers, that’s approx 2.1ms of pure overhead per token. At 150+ TPS, this compounds fast.
Confirmed independently by SGLang issue #17526 (Blackwell B300 benchmarks): BF16 KV achieved 6,018 tok/s vs FP8 KV’s 4,886 tok/s - a 23% gap.
Lesson learned: don’t assume what worked on Hopper works on Blackwell. Benchmark everything.

What Didn’t Work
NVFP4 - NVIDIA’s FP4 quantized checkpoint (44% smaller). No EAGLE support - MTP weights are missing. Without EAGLE, TTFT goes from 3.5s to 17.9s. Required patches to modelopt_quant.py. TP=4 crashes with cuDNN GEMM errors. Even at TP=8: 117 TPS vs 165 with FP8+EAGLE. Dead end.
FA4 + EAGLE - Already mentioned. Prefill-only, draft worker incompatible.
thinking_budget + EAGLE - SGLang’s MoeThinkingBudgetLogitProcessor uses output_ids to count reasoning tokens, but EAGLE draft tokens aren’t committed to output_ids until verified. The processor never sees enough tokens to trigger the budget cap. Broken.
The TTS Stack
Nerd mode: slightly lower intensity
Our voice system needed to serve 100 concurrent streams with RTF (real-time factor) below 0.25 on a single B200.
We had a starting point. It was slow. It needed love.
Plaza came in and pushed GPU, TensorRT, and Triton inference server to their absolute limits. Good benchmarking was everything - you can’t optimize what you can’t measure.
The funny mishap: today, on launch day, we were burst-testing the production server. The Triton inference server handled it like a champ. But we accidentally killed our FastAPI/REST server. Multiple times. Uvicorn just... gave up.
Panic was involved. Production server. Launch day. Classic startup moment.
We fixed it. Shipped it. Moved on.
RTF 0.22 / 1st user, approx 0.5 under heavy load. Single B200. 100 concurrent streams. BF16 precision. It works.
The Grind
One full month of constant crunch. For most of the team.
The last few days were the hardest. Daily releases. Sometimes multiple releases per day. Every morning a new list of bugs. Every evening a new build.
There were multiple moments of “this will NOT ship today”. And “this will NOT ship tomorrow”. And “are we sure this is going to ship at all?”
Startup life. Bootstrapping with limited funding means always being on the bleeding edge. You don’t have the luxury of “let’s wait until it’s perfect”. You ship when it works well enough to not embarrass yourself, and you fix the rest live.
We have custom monitoring dashboards for everything now. NIA metrics: total throughput, EAGLE acceptance rate, active requests per minute, TTFT. TTS metrics: concurrent inferences per second, RTF. When something breaks at 2am, we know exactly where to look.
It broke at 2am more than once this month.
What’s next?
The demo is live. Go break it: omea.ai
Tell us what sucks. We’ll fix it tomorrow. That’s the deal.

The Viking story is just the beginning. One story, one world, one proof of what NIA can do. But we have plans. Many plans.
B300 experiments are on the roadmap. NVFP4 might be salvageable if we can get EAGLE weights working. FA4 might become usable for non-EAGLE workloads.
But right now? Right now we ship. We watch the metrics. We fix the bugs users find. We iterate.
Less talking, more building.
Max

The humans who made this possible
Michal Pena (a.k.a. Cyb0org) - cofounder, MLOps wizard, DevOps firefighter, the guy who deals with our programmers when they (or me) want to burn everything (or everyone) down. Golden supporter from day one. The aggressive fine-tuning and clever reasoning cut-down methods I (didn’t) mentioned? His work. Proprietary magic.
Justine - my wife, my sanity anchor, and also (plot twist) a data scientist who ended up debugging game-designer related stuff. When I disappeared into GPU kernel hell for weeks, she kept everything else running. Everything.
Darek - Game Director. Led the charge on the Viking story. “Small and simple” became “sandbox with unlimited freedom” because he refused to ship anything he wasn’t proud of.
Przemek Kuśmierek - constant, relentless support. Even while running Migam. Even while dealing with his own chaos. Always there.
Plaza - for turning our TTS stack from “it works, kinda” into “100 concurrent streams on a single GPU”. The Triton optimization work was clutch.
Pawel Morkisz - the first person to kick my fat ass into taking things (a.k.a. TRT) seriously. Sometimes support doesn’t look like code reviews or investor intros. Sometimes it’s just showing up for a steak or salad in San Jose and reminding you to be a better man. That matters more than you’d think.
And to everyone else who believed in this before it was real - the investors who took meetings when we had nothing but slides, the advisors who answered late-night questions, the friends who just showed up when it mattered.
You know who you are.
This one’s for you.

PS. The website? Built with Claude, not WordPress. Obviously.
PS.2 If you want to go even deeper on the technical stuff - the exact FlashInfer version pinning, the MNNVL stub hack, the reasoning parser swap - hit me up. I have opinions. Many opinions.
Great to see a product running
Gonna try it out very soon.